Introducción.
 Aunque la materia Bases de Datos tiene un carácter propedéutico para la disciplina de los sistemas de bases de datos y el área más general de sistemas de información, es necesario conocer cuál ha sido la evolución y estado actual de la tecnología de bases de datos, con el objetivo de estar preparados para los cambios que, inevitablemente, se van a dar en el área de las bases de datos y los sistemas de información.
Aunque la materia Bases de Datos tiene un carácter propedéutico para la disciplina de los sistemas de bases de datos y el área más general de sistemas de información, es necesario conocer cuál ha sido la evolución y estado actual de la tecnología de bases de datos, con el objetivo de estar preparados para los cambios que, inevitablemente, se van a dar en el área de las bases de datos y los sistemas de información.Para ello, en este informe se relata brevemente la evolución de los sistemas de bases de datos, centrándose en los fundamentos de la tecnología actual y su motivación. Haremos un repaso de las nociones y evolución básicas de los modelos pre-relacionales, relacionales, objetuales y objeto-relacional, las bases de datos paralelas y distribuidas, multimedia, los almacenes de datos, la relación entre las bases de datos y la web, así como otras áreas y aplicaciones. Esto nos lleva a evaluar la situación actual, especialmente las nuevas demandas sobre sistemas de información exigidas por el aumento de interconectividad, los nuevos imperativos de publicación e intercambio de información, los datos semiestructurados y el estándar XML, así como el análisis de datos para la toma de decisión y los avances y perspectivas en las “bases de conocimiento”. Se comentan también las líneas de investigación abiertas más importantes en el área y una opinión personal sobre hacia donde parece dirigirse la disciplina. Finalmente, se estudia sucintamente la sociología de la disciplina, su interrelación con otras disciplinas del área de Lenguajes y Sistemas Informáticos y las organizaciones, congresos y publicaciones más importantes.
Evolución de los Sistemas de Bases de Datos.
Los sistemas de información existen desde las primeras civilizaciones. El concepto más esencial de sistema de información no ha variado desde los censos romanos, por poner un ejemplo. Los datos se recopilaban, se estructuraban, se centralizaban y se almacenaban convenientemente. El objetivo inmediato de este proceso era poder recuperar estos mismos datos u otros datos derivados de ellos en cualquier momento, sin necesidad de volverlos a recopilar, paso que solía ser el más costoso o incluso irrepetible. El objetivo ulterior de un sistema de información, no obstante, era proporcionar a los usuarios información fidedigna sobre el dominio que representaban, con el objetivo de tomar decisiones y realizar acciones más pertinentes que las que se realizarían sin dicha información.
Llamamos base de datos justamente a esta colección de datos recopilados y estructurados que existe durante un periodo de tiempo. Por ejemplo, un libro contable, debido a su estructura, se puede considerar una base de datos. Una novela, por el contrario, no tiene casi estructura, y no se suele considerar una base de datos.
Generalmente, un sistema de información consta de una o más bases de datos, junto con los medios para almacenarlas y gestionarlas, sus usuarios y sus administradores.
Hoy en día, sin embargo, solemos asociar las bases de datos con los ordenadores, y su gestión no suele ser manual, sino altamente automatizada. Más concretamente, la tecnología actual insta a la delegación de la gestión de una base de datos a unos tipos de aplicaciones software específicas denominadas sistemas de gestión de bases de datos (SGBD) o, simplemente, sistemas de bases de datos. Por esta razón, hablar de la tecnología de bases de datos es prácticamente lo mismo que hablar de la tecnología de los sistemas de gestión de bases de datos.
Las funciones básicas de un sistema de gestión de base de datos son (Ullman & Widom 1997)
- Permitir a los usuarios crear nuevas bases de datos y especificar su estructura, utilizando un lenguaje o interfaz especializado, llamado lenguaje o interfaz de definición de datos.
- Dar a los usuarios la posibilidad de consultar los datos (es decir, recuperarlos parcial o totalmente) y modificarlos, utilizando un lenguaje o interfaz apropiado, generalmente llamado lenguaje de consulta o lenguaje de manipulación de datos.
- Permitir el almacenamiento de grandes cantidades de datos durante un largo periodo de tiempo, manteniéndolos seguros de accidentes o uso no autorizado y permitiendo un acceso eficiente a los datos para consultas y modificaciones.
- Controlar el acceso a los datos de muchos usuarios a la vez, impidiendo que las acciones de un usuario puedan afectar a las acciones de otro sobre datos diferentes y que el acceso simultáneo no corrompa los datos.
Primeros Sistemas de Base de Datos.
Los primeros sistemas de bases de datos aparecieron a finales de los cincuenta. En este periodo, muchas compañías se fueron dando cuenta de que los primeros sistemas informáticos brindaban la posibilidad de aplicar soluciones mecánicas más baratas y eficientes. Los primeros sistemas evolucionaron de los sistemas de ficheros que proporcionaban almacenamiento de grandes cantidades de datos durante un largo periodo de tiempo. Sin embargo, los sistemas de ficheros no garantizaban generalmente que los datos no se perdían ante fallos bastante triviales, y se basaban casi exclusivamente en recuperación por copia de seguridad.
Además, los sistemas de ficheros proporcionaban de una manera limitada dar a los usuarios la posibilidad de consultar los datos, es decir, un lenguaje de consultas para los datos en los ficheros. El soporte de estos sistemas para permitir a los usuarios crear nuevas bases de datos también era limitado y de muy bajo nivel. Finalmente, los sistemas de ficheros no satisfacen el acceso concurrente a ficheros por parte de varios usuarios o procesos, un sistema de ficheros no previene generalmente las situaciones en la que dos usuarios modifican el mismo fichero al mismo tiempo, con lo que los cambios realizados por uno de ellos no llegan aparecer definitivamente en el fichero. Las primeras aplicaciones importantes de los sistemas de ficheros fueron aquellas en la que los datos estaban compuestos de partes bien diferenciadas y la interrelación entre ellas era reducida. Algunos ejemplos de estas aplicaciones eran los sistemas de reserva (p.ej. reserva e información de vuelos), los sistemas bancarios donde se almacenaban las operaciones secuencialmente y luego se procesaban, y los primeros sistemas de organización corporativos (ventas, facturación, nóminas, etc.).
Los primeros verdaderos SGBDs, evolucionados de los sistemas de ficheros, obligaban a que el usuario visualizara los datos de manera muy parecida a como se almacenaban. Los primeros sistemas de ficheros habían logrado pasar del código máquina a un lenguaje ensamblador con ciertas instrucciones de acceso a disco, nociones que se pueden ver en sistemas todavía en funcionamiento hoy en día, tales como la línea AS de IBM.
No es de extrañar que con este nivel de abstracción la manera de recuperar los datos estaba estrechamente ligada al lenguaje de programación utilizado. Un avance importante lo constituyó el comité formado en la COnference on DAta SYstems and Languages, CODASYL, en 1960 estableciendo el COmmon Business-Oriented Language (COBOL) como un lenguaje estándar para interrelacionar con datos almacenados en ficheros. Aunque hoy en día puede parecer un lenguaje “muy físico”, en aquella época representó lo que se vinieron a llamar los lenguajes de programación de tercera generación. Las instrucciones específicas de un programa Cobol para tratamiento de ficheros eran las de abrir un fichero, leer un fichero y añadir un registro a un fichero. Lo típico en gestión de datos en esta época era un fichero ‘batch’ de transacciones que se aplicaba a un maestro viejo en cinta, produciendo como resultado un nuevo maestro también en cinta y la impresión para el siguiente día de trabajo.
Pero pronto los discos magnéticos empezaron a sustituir a las cintas magnéticas, lo que supuso una reconcepción del almacenamiento, al pasarse del acceso secuencial al acceso aleatorio (este paso es el que se conoce como el paso de los sistemas de bases de datos de primera a segunda generación).
Durante los sesenta empezaron a aparecer distintos modelos de datos para describir la estructura de la información en una base de datos, con el objetivo de conseguir una independencia un poco mayor entre las aplicaciones y la organización física de los datos. Esto se consiguió inicialmente mediante la abstracción entre varios (sub)esquemas externos para las aplicaciones frente a la organización física de los mismos. Esta separación en dos niveles fue propuesta por el grupo Data Base Task Group (DBTG) del comité CODASYL.
Los modelos más popularizados fueron el modelo jerárquico o basado en árboles, y el modelo en red o basado en grafos. Los SGBD acordes con estos modelos se conocieron como SGBD de tercera generación.
Principales características de las bases de datos.
1- Independencia lógica y física de los datos.
2- Control centralizado de los datos.
3- Integridad de los datos.
4- Minimización de redundancias.
5- Independencias de los datos y las aplicaciones
6- Acceso concurrente a los datos.
Independencia lógica y física de los datos.
Independencia física de los datos
El hardware de almacenamiento y las técnicas físicas de almacenamiento podrán ser modificados sin obligar a la modificación de los programas de aplicación
Independencia lógica de los datos
Podrán agregarse nuevos ítems de datos, o expandirse la estructura lógica general, sin que sea necesario reescribir los programas de aplicación existentes, solo se modificara la aplicación que los utiliza.
Control centralizado de los datos.
Brinda la posibilidad de control centralizado sobre los recursos de información de una empresa entera u organización. Antiguamente cada aplicación tiene sus propios archivos privados. La función fundamental del Administrador de Bases de Datos (DBA) es garantizar la seguridad de los datos; los mismos datos son reconocidos como un patrimonio de las organizaciones las cuales requieren una responsabilidad centralizada.
Integridad de los datos.
Integridad es garantizar que los datos de la base de datos sean exactos. El control centralizado de la base de datos ayuda a evitar la inconsistencia de los datos, por el mismo hecho de encontrarse en un solo lugar y mediante medidas de seguridad, restricciones y controles para evitar inconsistencias.
Minimización de redundancias.
Como distintas aplicaciones se conectan a la base de datos, no hace falta tanta repetición de datos, como en antaño que los distintos programas tenían su colección de datos, muchas veces redundados.
Independencias de los datos y las aplicaciones.
Se refiere a que podemos quitar un programa que se conecta a la base y cambiarlo por otro sin tener que modificar la base. Lo mismo a la inversa podemos cambiar la base de datos y debería ser transparente para los programas que se conectan a ella.
Acceso concurrente a los datos.
Diferentes usuarios pueden acceder simultáneamente a la base mediante técnicas de bloqueo o cerrado de datos accedidos.
Componentes de un sistema de base de datos.
- Hardware. Máquinas en las que se almacenan las bases de datos. Incorporan unidades de almacenamiento masivo para este fin.
- Software. Es el sistema gestor de bases de datos. El encargado de administrar las bases de datos.
- Datos. Incluyen los datos que se necesitan almacenar y los metadatos que son datos que sirven para describir lo que se almacena en la base de datos.
- Usuarios. Personas que manipulan los datos del sistema. Hay diferentes categorías según sus funciones y según su grado de uso.
Tipos de base de datos.
• Bases de datos jerárquicas
• Base de datos de red
• Bases de datos relacionales
• Bases de datos multidimensionales
• Bases de datos orientadas a objetos
Bases de datos jerárquicas.
Éstas son bases de datos que, como su nombre indica, almacenan su información en una estructura jerárquica. En este modelo los datos se organizan en una forma similar a un árbol (visto al revés), en donde un nodo padre de información puede tener varios hijos. El nodo que no tiene padres es llamado raíz, y a los nodos que no tienen hijos se los conoce como hojas.
Las bases de datos jerárquicas son especialmente útiles en el caso de aplicaciones que manejan un gran volumen de información y datos muy compartidos permitiendo crear estructuras estables y de gran rendimiento. Una de las principales limitaciones de este modelo es su incapacidad de representar eficientemente la redundancia de datos.
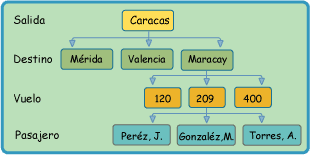
Bases de datos de red.
Éste es un modelo ligeramente distinto del jerárquico; su diferencia fundamental es la modificación del concepto de nodo: se permite que un mismo nodo tenga varios padres (posibilidad no permitida en el modelo jerárquico).
Fue una gran mejora con respecto al modelo jerárquico, ya que ofrecía una solución eficiente al problema de redundancia de datos; pero, aun así, la dificultad que significa administrar la información en una base de datos de red ha significado que sea un modelo utilizado en su mayoría por programadores más que por usuarios finales.

Base de datos Relacional.
Una base de datos relacional es una base de datos que cumple con el modelo relacional, el cual es el modelo más utilizado en la actualidad para implementar bases de datos ya planificadas. Permiten establecer interconexiones (relaciones) entre los datos (que están guardados en tablas), y a través de dichas conexiones relacionar los datos de ambas tablas, de ahí proviene su nombre: "Modelo Relacional".
Características
- Una base de datos relacional se compone de varias tablas o relaciones.
- No pueden existir dos tablas con el mismo nombre ni registro.
- Cada tabla es a su vez un conjunto de registros (filas y columnas).
- La relación entre una tabla padre y un hijo se lleva a cabo por medio de las claves primarias y ajenas (o foráneas).
- Las claves primarias son la clave principal de un registro dentro de una tabla y éstas deben cumplir con la integridad de datos.
- Las claves ajenas se colocan en la tabla hija, contienen el mismo valor que la clave primaria del registro padre; por medio de éstas se hacen las relaciones.

{kind=link}
Bases de datos multidimensionales.
Visualización de los datos mediante un cubo
La vista de los datos como un cubo es una extensión natural de como la mayoría de los usuarios de negocios interactúan con los datos.
Ellos ven a un problema de negocios en términos de un cierto número de componentes (dimensiones) tales como productos, tiempo, regiones, fabricantes, o artículos.
Los usuarios de negocios desean poder analizar un conjunto de números usando cualquier par de estos componentes, como así también poder intercambiarlos para lograr distintas vistas.
OLAP
Los sistemas OLAP son bases de datos orientadas al procesamiento analítico. Este análisis suele implicar, generalmente, la lectura de grandes cantidades de datos para llegar a extraer algún tipo de información útil: tendencias de ventas, patrones de comportamiento de los consumidores, elaboración de informes complejos, etc.. Este sistema es típico de los datamarts. Los sistemas de ayuda a la toma de decisiones se presentan en varios formatos, incluidos los sistemas OLAP y los sistemas de recopilación de datos.
En un modelo de datos OLAP, la información es vista como cubos, los cuales consisten de categorías descriptivas (dimensiones) y valores cuantitativos (medidas). El modelo de datos multidimensional simplifica a los usuarios formular consultas complejas, arreglar datos en un reporte, cambiar de datos resumidos a datos detallados y filtrar o rebanar los datos en subconjuntos significativos.
Visualización de los datos
Las herramientas de procesamiento analítico en línea (online analytical processing, OLAP) ayudan a los analistas a ver los datos resumidos de diferentes maneras, de manera que puedan obtener una perspectiva del funcionamiento de la organización.
Se ve a un problema de negocios en términos de un cierto número de componentes (dimensiones) tales como productos, tiempo, regiones, fabricantes, o artículos. Los usuarios de negocios desean poder analizar un conjunto de números usando cualquier par de estos componentes, como así también poder intercambiarlos para lograr distintas vistas.

Ejemplo ventas de productos en diferentes regiones:

Para un mayor análisis se desearía ver cómo se desarrollan las ventas por producto en un periodo dato. Para hacer esto, se necesitarían abrir varias tablas simultáneamente.

Esto mismo en un cubo lo tratamos como dimensiones una seria la de tiempo, otra de productos y una última región.

• ¿Cómo se venden los productos en cada región en un mes dado? Esto es equivalente a ver Producto por Región en un mes dado.
• ¿Qué regiones han mejorado las ventas de un producto dado a través del tiempo? Esto es equivalente a Región por Tiempo de un producto dado.
• ¿Cómo se venden los productos a través del tiempo en una región dada? Esto es equivalente a Producto por Tiempo en una región dada.
Bases de datos orientadas a objetos.
En una base de datos orientada a objetos, la información se representa mediante objetos como los presentes en la programación orientada a objetos.
Las bases de datos orientadas a objetos se diseñan para trabajar bien en conjunción con lenguajes de programación orientados a objetos. Dichos objetos se extienden en los lenguajes como datos persistentes de forma transparente, control de concurrencia, recuperación de datos, consultas asociativas y otras capacidades.

Alguien podría pensar, por tanto, que las bases de datos orientadas a objetos deberían de haber superado en la práctica a las relacionales. De hecho, a veces se denominan postrelacionales. No obstante, después de más 15 años, el mercado de las bases de datos orientadas a objetos no supone más de un 5% del mercado de las relacionales, como se puede ver en las siguientes gráficas:
